In this guide, I’ll walk you through parsing a docx file and mapping it to a Java Plain Old Java Object (POJO). Grab the complete code for this tutorial from GitHub.
Understanding Docx Format
Docx, a standard document format introduced in 2007 alongside Microsoft Office 2007, encapsulates documents within a zip archive as distinct folders and files, unlike the previous binary file format. Docx files are accessible via Microsoft Word 2007 onwards and various open-source office solutions like LibreOffice and OpenOffice. To peek inside a docx file, simply switch its extension to .zip and delve into the archive with any file archiver.
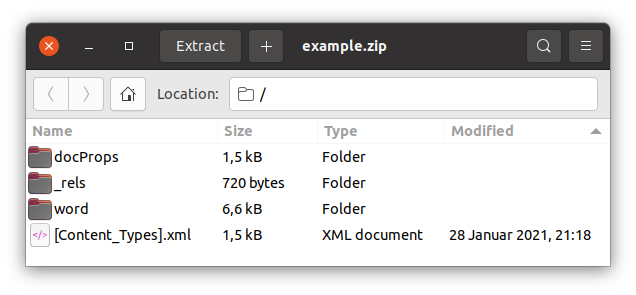
Dive into the folder named ‚word‘ to find the file document.xml, which houses the primary text and some style information. This tutorial will center around this file. For a deeper dive into docx structure, head to Anatomy of OOXML.
We’ll kick things off by extracting the docx archive, then read and map the word/document.xml file to a Java object for further tinkering.
Preparing an Example Docx File
It’s time to craft a simple docx file to play with throughout this tutorial. I’ve whipped up a brief text with basic formatting:

Extracting document.xml
To access the contents of document.xml, we’ll treat the docx file as a typical zip file. Java simplifies this with its ZipFile class. We instantiate a new ZipFile object, passing our docx file to the constructor. The getEntry(String name) method helps locate the desired entry—in our case, word/document.xml. Finally, we retrieve the input stream of this entry to read its contents.
public static InputStream getStreamToDocumentXml(File docx) throws IOException {
ZipFile zipFile = new ZipFile(docx);
ZipEntry zipEntry = zipFile.getEntry("word/document.xml");
return zipFile.getInputStream(zipEntry);
}Invoke this method and store its return value as an InputStream:
String fileName = "example.docx"; InputStream inputStream = Unzipper.getStreamToDocumentXml(new File(fileName));
Inspecting the Extracted Content
For validation, let’s fetch the document.xml content as a string.
String text = new BufferedReader(
new InputStreamReader(inputStream, StandardCharsets.UTF_8))
.lines()
.collect(Collectors.joining("\n"));
System.out.println(text);Can you spot and interpret our example text in the resultant XML?
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <w:document xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" mc:Ignorable="w14 wp14"><w:body><w:p><w:pPr><w:pStyle w:val="Normal"/><w:bidi w:val="0"/><w:jc w:val="left"/><w:rPr><w:color w:val="2A6099"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr></w:pPr><w:r><w:rPr><w:color w:val="2A6099"/><w:sz w:val="28"/><w:szCs w:val="28"/><w:u w:val="single"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr><w:t>This</w:t></w:r><w:r><w:rPr><w:color w:val="2A6099"/><w:sz w:val="28"/><w:szCs w:val="28"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr><w:t xml:space="preserve"> is my </w:t></w:r><w:r><w:rPr><w:b/><w:bCs/><w:i/><w:iCs/><w:color w:val="2A6099"/><w:sz w:val="28"/><w:szCs w:val="28"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr><w:t>example</w:t></w:r><w:r><w:rPr><w:color w:val="2A6099"/><w:sz w:val="28"/><w:szCs w:val="28"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr><w:t xml:space="preserve"> text.</w:t></w:r></w:p><w:sectPr><w:type w:val="nextPage"/><w:pgSz w:w="11906" w:h="16838"/><w:pgMar w:left="1134" w:right="1134" w:header="0" w:top="1134" w:footer="0" w:bottom="1134" w:gutter="0"/><w:pgNumType w:fmt="decimal"/><w:formProt w:val="false"/><w:textDirection w:val="lrTb"/><w:docGrid w:type="default" w:linePitch="100" w:charSpace="0"/></w:sectPr></w:body></w:document>
This XML adheres to a particular structure, highlighted below. This depiction only showcases the elements pertinent to our example.
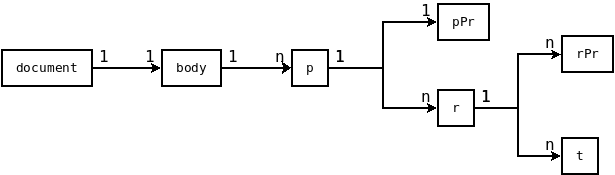
Delve deeper into the XML structure here.
Mapping Content to Java Objects
Now that we’ve accessed the docx contents, let’s parse and map them to a POJO. This requires setting up some tools and crafting a few POJOs to mirror our XML file structure.
Tool Setup
- Maven
- A go-to for build automation.
- JAXB
- A handy tool for marrying XML documents to Java objects. I’ll be using the Eclipse implementation.
- Lombok
- A lifesaver for cutting down boilerplate code.
Include the necessary dependencies in your pom.xml:
<dependency>
<groupId>jakarta.xml.bind</groupId>
<artifactId>jakarta.xml.bind-api</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>3.0.0</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>Defining POJOs
To map document.xml to our Java object, we’ll design classes mirroring the file structure.
A document encompasses a single node document, housing a single node body. We’ll only need getters to later access its contents, keeping the fields private. Leveraging Lombok and JAXB annotations, our document element’s POJO (or DTO) would appear as follows:
@Getter
@FieldDefaults(level = AccessLevel.PRIVATE)
@XmlRootElement(name = "document")
@XmlAccessorType(XmlAccessType.FIELD)
public class DJMDocument {
@XmlElement(name = "body")
DJMBody body;
}As a body hosts multiple paragraphs, we’ll map paragraphs to a list. We’ll keep the setter private for internal use within the class itself. The POJO for the body is:
@FieldDefaults(level = AccessLevel.PRIVATE)
public class DJMBody {
List<BodyElement> bodyElements;
@XmlElements({
@XmlElement(name = "p", type = DJMParagraph.class)
})
public List<BodyElement> getBodyElements() {
return bodyElements;
}
private void setBodyElements(List<BodyElement> bodyElements) {
this.bodyElements = bodyElements;
}
}Continue in a similar vein for each element you wish to map. For a deeper dive, check out the full example project on my GitHub.
Verifying the Outcome
Now that our classes are set, it’s time to validate by fetching the docx text. The method below navigates through the document, locates all runs, appends their texts to a StringBuilder, and returns the result:
public static String getTextFromDocument(DJMDocument djmDocument){
StringBuilder stringBuilder = new StringBuilder();
// Different elements can be of type BodyElement
for (BodyElement bodyElement : djmDocument.getBody().getBodyElements()) {
// Check, if current BodyElement is of type DJMParagraph
if (bodyElement instanceof DJMParagraph) {
DJMParagraph dJMParagraph = (DJMParagraph) bodyElement;
// Different elements can be of type ParagraphElement
for (ParagraphElement paragraphElement : dJMParagraph.getParagraphElements()) {
// Check, if current ParagraphElement is of type DJMRun
if (paragraphElement instanceof DJMRun) {
DJMRun dJMRun = (DJMRun) paragraphElement;
stringBuilder.append(dJMRun.getText());
}
}
}
}
return stringBuilder.toString();
}Running this method retrieves our document text:
This is my example text.
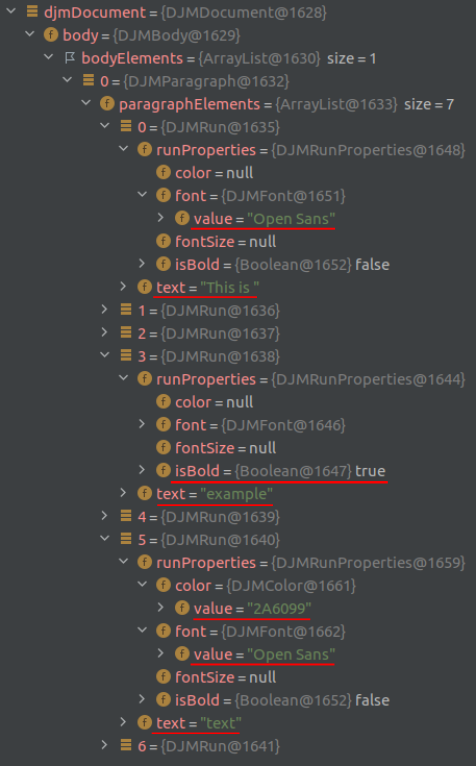
To access text formatting like colors and fonts, a debugger can be employed during runtime to inspect our newly crafted document object. As expected, it reveals all set attributes in the docx, including font, color, and bold formatting.
A slight tweak to our method enables us to collect all bold words into a list:
public static List<String> getBoldWords(DJMDocument djmDocument) {
List<String> boldWords = new ArrayList<>();
// Different elements can be of type BodyElement
for (BodyElement bodyElement : djmDocument.getBody().getBodyElements()) {
// Check, if current BodyElement is of type DJMParagraph
if (bodyElement instanceof DJMParagraph) {
DJMParagraph dJMParagraph = (DJMParagraph) bodyElement;
// Different elements can be of type ParagraphElement
for (ParagraphElement paragraphElement : dJMParagraph.getParagraphElements()) {
// Check, if current ParagraphElement is of type DJMRun
if (paragraphElement instanceof DJMRun) {
DJMRun dJMRun = (DJMRun) paragraphElement;
boolean isBold = dJMRun.getRunProperties().isBold();
if (isBold) {
String text = dJMRun.getText();
boldWords.add(text);
}
}
}
}
}
return boldWords;
}Executing this method accurately yields:
[my, example]
What’s Next?
Grab the final code from this tutorial on GitHub. Feel free to clone the project, tinker around, and extend it with additional elements like images, tables, and lists. For a more intricate project with extra mapped elements, check out DocxJavaMapper.
Explore another project of mine, Docx2PDF, where I convert a docx to a pdf using this mapping technique.